SE6023 Lab4 Spark & Scala
Introducing Spark

What is Apache Spark?
- An open source cluster computing framework
- Fast and general engine for large-scale data processing
- With libraries for SQL, streaming, advanced analytics
- Requires a cluster manager and a distributed storage system
- Cluster manager
Hadoop YARN, Apache Mesos, …
- Distributed storage system
HDFS, Cassandra, OpenStack Swift, Amazon S3, …
Why Spark?
In
2014 Gray Sort competition, a 3rd-party benchmark measuring how fast a
system can sort 100 TB of data, shows that Spark has performance
advantages than plain MapReduce:
- Hadoop MapReduce used 2100 machines and took 72 minutes.
- Spark on 206 EC2 machines, sorting the same data in 23 minutes

Source: Databricks blog, Sort benchmark, Spark SQL on SIGMOD 2015
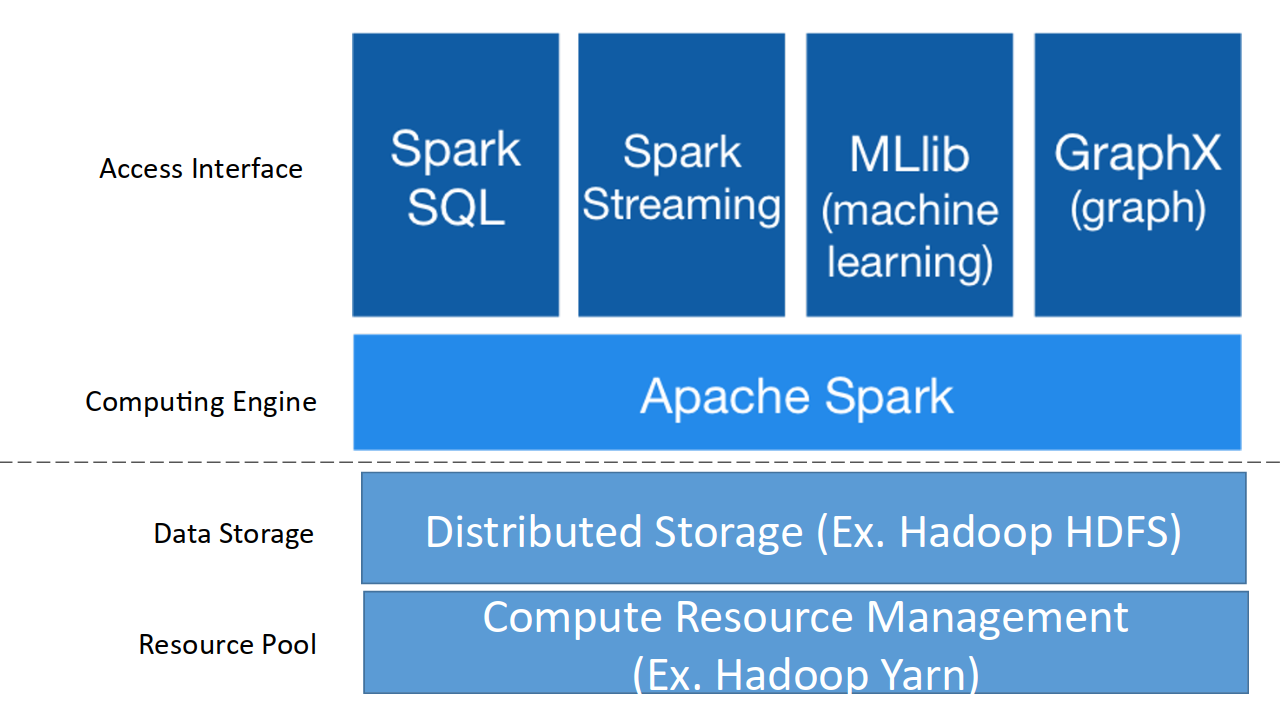
Spark Stack
- Spark SQL
- Spark Streaming: stream processing of live data streams

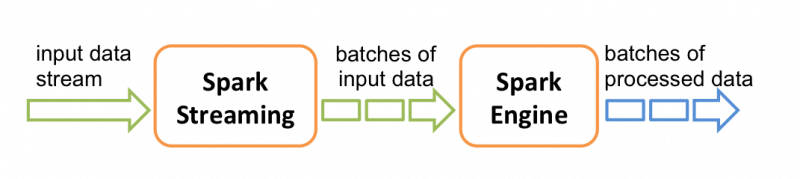
Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis, or TCP sockets (Source: Introduction to Spark Streaming)
- MLlib: Spark’s scalable machine learning library
- GraphX: Spark’s API for graphs and graph-parallel computation
Spark Interactive Shell
We will first introduce the API through Spark’s interactive shell:
- In Python:
pyspark
- In Scala:
spark-shell
then show you how to write RDD applications in Java, Scala, and Python.

Source: https://spark.apache.org/docs/latest/quick-start.html
Spark APIs
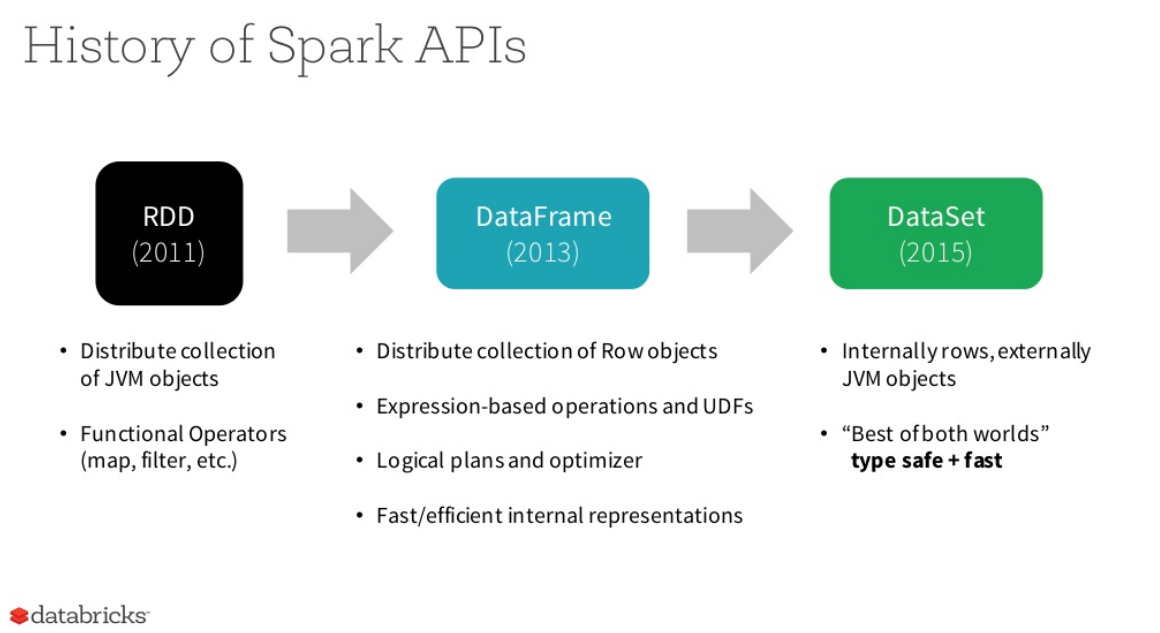
Spark now provide 3 APIs to make different type of workload easier and more optimized.
- RDD
Stands for Resilient Distributed Dataset, RDD is an immutable distributed collection of elements of your data,
partitioned across nodes in your cluster that can be operated in
parallel with a low-level API that offers transformations and actions.
It is suitable for low-level control on datasets and unstructured data, and the newer API(DataFrames/Datasets) are built on top of RDDs.
We will mainly discuss RDD in this lab session.
- DataFrame
Like an RDD, DataFrame is an immutable distributed collection of data. But data is organized into named column
which works like a table in a relational database system. It allows
higher-level abstraction and provides domain-specific launuage API to
manipulate distributed data, make Spark accessible to people other than
data engineers.
DataFrame will be merged with Datasets API.
- DataSet
A Dataset is a strongly typed collection of domain-specific objects that
can be transformed in parallel using functional or relational
operations. Each Dataset also has an untyped view called a DataFrame,
which is a Dataset of Row.
DataSet API can:
- Achieve runtime type-safety by static-typing
- Provide high-level abstraction and custom view into structured and semi-structured data
- Use rich semantics. filters, SQL queries… and domain specific APIs
- Achieve higher space efficiency and performance than RDDs automatically
Source: A Tale of Three Apache Spark APIs
Core Spark Concept: Resilient Distributed Dataset (RDD)
RDD is a read-only collection of objects that is partitioned across multiple machines in a cluster.
In a typical Spark program, one or more RDDs are loaded as input and through a series of transformations are turned into a set of target RDDs, which have an action performed on them (such as computing a result or writing them to persistent storage).
The term “resilient” in “Resilient Distributed Dataset” refers to the fact that Spark can automatically reconstruct a lost partition by recomputing it from the RDDs that it was computed from.
-Hadoop: The Definitive Guide, 4th Edition, Page 550
- A fault tolerant, distributed collection of objects.
- In
Spark, every task is expressed in following ways:
- Creating new
RDD(s)
- Transforming existing
RDD(s)
- Calling operations on
RDD(s)
RDD Operations
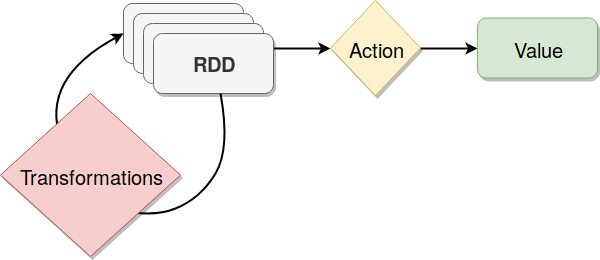
RDDs support two types of operations:
- Transformations: Create a new dataset from an existing one
map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues …
- Actions: Return a value to the driver program after running computation on the dataset
collect, reduce, count, save, lookupKey …
Source
RDD of Strings
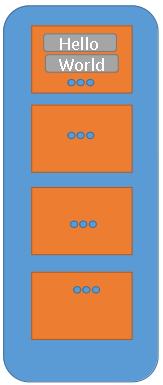
- Immutable Collection of Objects
- Partitioned and Distributed
- Stored in Memory
- Partitions recomputed on Failure
RDD Fault Tolerance in Spark
If the original RDD that was used to create your current partition also
isn’t there (neither in memory or on disk) then Spark will have to go
one step back again and recompute the previous RDD. In the worst case
scenario Spark will have to go all the way back to the original data.
More Information:
Different between Hadoop MapReduce and RDD
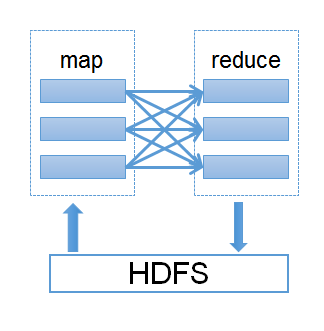
Iterative Operations
-
On MapReduce
Incurs substantial overheads due to data replication, disk I/O, and serialization
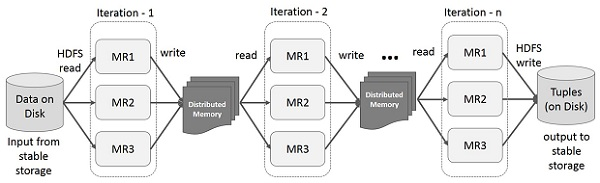
-
On Spark RDD
Store intermediate results in a distributed memory
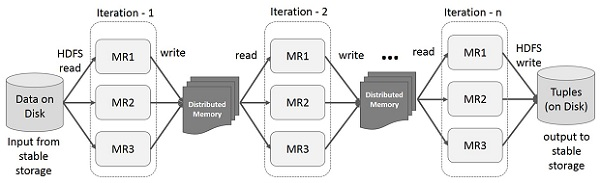
Note
If the Distributed memory (RAM) is not sufficient to store intermediate
results (State of the JOB), then it will store those results on the
disk.
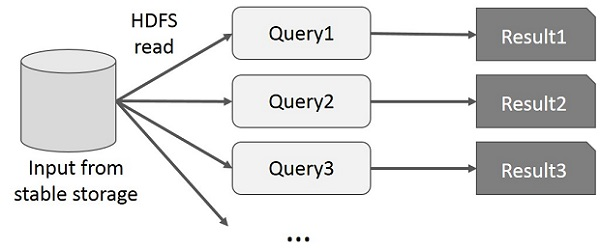
Interactive Operations
-
On MapReduce
Each query will do the disk I/O on the stable storage
-
On Spark RDD
If different queries are run on the same set of data repeatedly, this particular data can be kept in memory for better execution times.
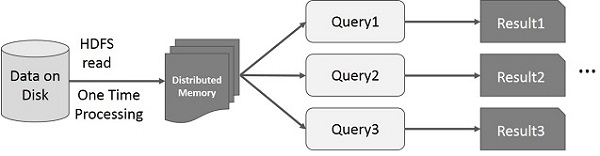
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory
(for much faster access when next time you query it)
Source: https://www.tutorialspoint.com/apache_spark/apache_spark_rdd.htm
Creating RDDs
There are two ways to create RDDs
- Parallelizing an existing collection in your driver program
- Referencing a dataset in an external storage system (shared file system, HDFS, HBase …)
1. Parallelizing Collections
- Created by calling
SparkContext’s parallelize method on an existing collection in your driver program (a Scala Seq).
- The elements of the collection are copied to form a distributed dataset that can be operated on in parallel.
Scala
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
distData.reduce((a, b) => a + b)
Python
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
2. Referencing a dataset
Spark supports
Text file RDDs can be created using SparkContext’s textFile
method. This method takes an URI for the file (either a local path on
the machine, or a hdfs://, s3a://, etc URI)
HTTP/HTTPS URLs is not supported.
Scala
val distFile = sc.textFile("data.txt")
distFile.map(s => s.length).reduce((a, b) => a + b)
Python
distFile = sc.textFile("data.txt")
rdd = sc.parallelize(range(1, 4)).map(lambda x: (x, "a" * x))
rdd.saveAsSequenceFile("path/to/file")
sorted(sc.sequenceFile("path/to/file").collect())
>>> [(1, u'a'), (2, u'aa'), (3, u'aaa')]
If you are using a path on the local filesystem, the file must also be accessible at the same path on worker nodes. Either copy the file to all workers or use a network-mounted shared file system.
RDD Operations
Basics
Scala
val lines = sc.textFile("data.txt")
val lineLengths = lines.map(s => s.length)
val totalLength = lineLengths.reduce((a, b) => a + b)
Python
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)
lines is merely a pointer to the file and is not loaded in memory.lineLengths defines lineLengths as the result of a map transformation
lineLengths is not immediately computed, due to laziness
reduce is and action. At this point Spark breaks the
computation into tasks to run on separate machines, and each machine
runs both its part of the map and a local reduction.
If we also wanted to use lineLengths again later, we could add:
lineLengths.persist()
before the reduce, which would cause lineLengths to be saved in memory after the first time it is computed.
Working with Key-Value Pairs
Scala
val lines = sc.textFile("data.txt")
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)
Python
lines = sc.textFile("data.txt")
pairs = lines.map(lambda s: (s, 1))
counts = pairs.reduceByKey(lambda a, b: a + b)
We could also use counts.sortByKey(), for example, to sort the pairs alphabetically, and finally counts.collect() to bring them back to the driver program as an array of objects.
- RDD API doc
- pair RDD functions doc
| Transformation |
Meaning |
| map(func) |
Return a new distributed dataset formed by passing each element of the source through a function func. |
| flatMap(func) |
Similar to map, but each input item can be mapped to 0 or more output items (so func should return a Seq rather than a single item). |
| Transformation |
Meaning |
| filter(func) |
Return a new dataset formed by selecting those elements of the source on which func returns true. |
| Transformation |
Meaning |
| reduceByKey(func, [numPartitions]) |
… |
Map
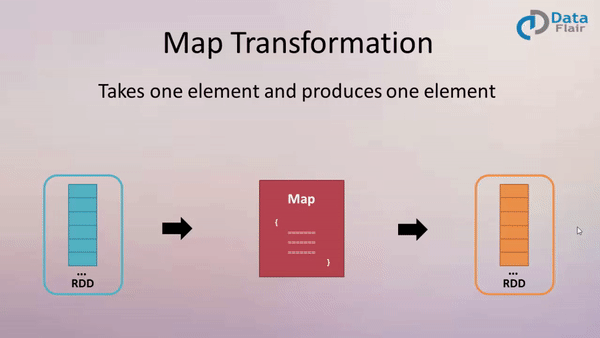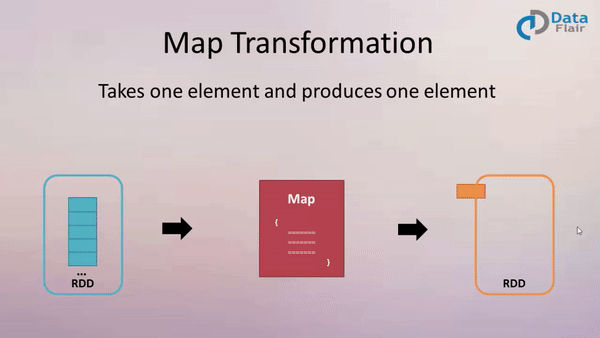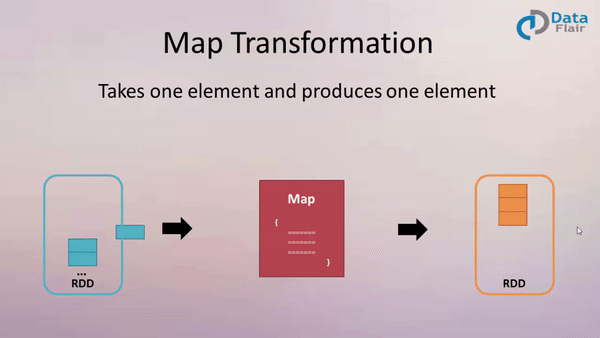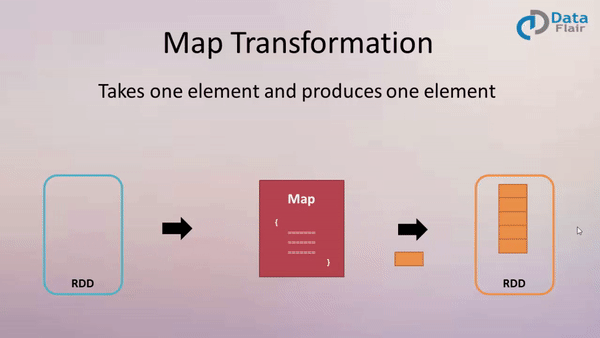
Example:
val newData = data.map (line => line.toUpperCase() )
or
val pairs = lines.map(s => (s, 1))
val counts = pairs.reduceByKey((a, b) => a + b)
FlatMap
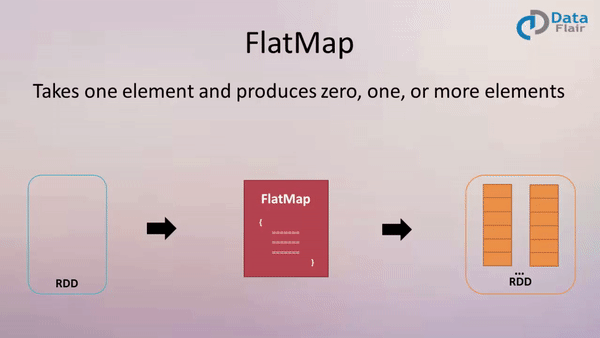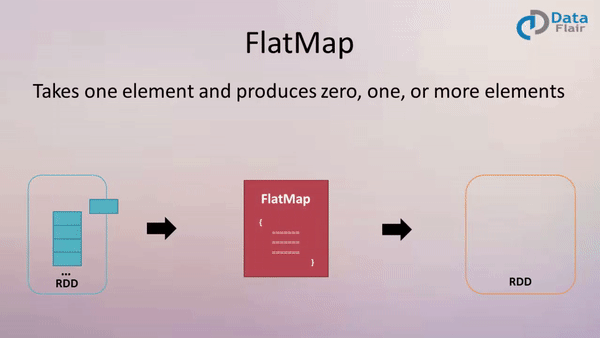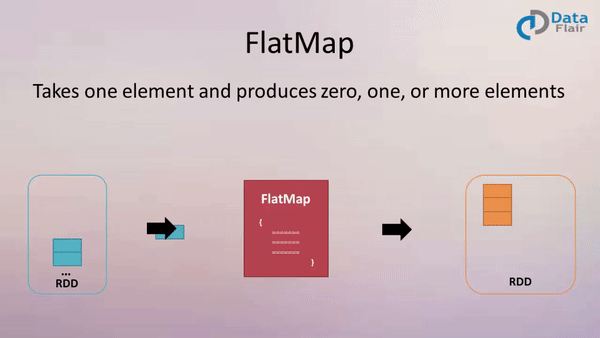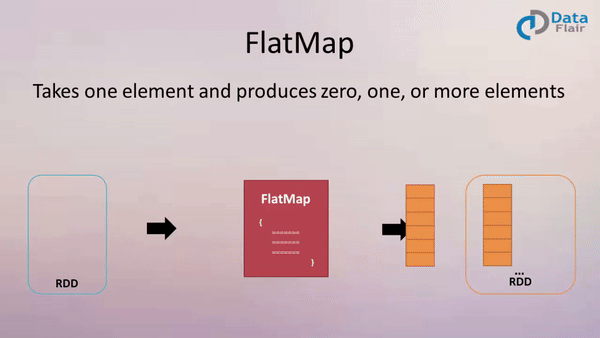
Example:
val result = data.flatMap(line => line.split(" ") )
Above flatMap transformation will convert a line into words. One word will be an individual element of the newly created RDD.
reduceByKey
MapReduce in Java
public class LineLengthReducer
extends Reducer<IntWritable,IntWritable,IntWritable,IntWritable> {
@Override
protected void reduce(IntWritable length, Iterable<IntWritable> counts, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable count : counts) {
sum += count.get();
}
context.write(length, new IntWritable(sum));
}
}
Spark Scala
val lengthCounts = lines.map(line => (line.length, 1)).reduceByKey(a,b=>a+b)
Sources
- Apache Spark Map vs FlatMap Operation
- Scala - can a lambda parameter match a tuple?
- reduceByKey: How does it work internally?
- How-to: Translate from MapReduce to Apache Spark
- How to use functions as variables (values) in Scala
Actions
| Action |
Meaning |
| reduce(func) |
Aggregate the elements of the dataset using a function func (which
takes two arguments and returns one). The function should be commutative
and associative so that it can be computed correctly in parallel. |
| collect() |
Return all the elements of the dataset as an array at the driver program. |
| count() |
Return the number of elements in the dataset. |
| foreach(func) |
… |
| saveAsTextFile(path) |
… |
| take(n) |
Return an array with the first n elements of the dataset. |
Reference
Examples
Source: https://spark.apache.org/examples.html
Using the Spark Shell
Scala: spark-shell
Python: pyspark
WordCount
Scala
val inputFilePath = "hdfs://hadoop-master:8020/user/a000000000/spark-wordcount-input.txt"
val textFile = sc.textFile(inputFilePath)
val counts = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.collect()
counts.saveAsTextFile("hdfs://...")
Python
inputFilePath = "hdfs://hadoop-master:8020/user/a000000000/spark-wordcount-input.txt"
text_file = sc.textFile(inputFilePath)
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.collect()
counts.saveAsTextFile("hdfs://...")
Pi Estimation
Scala
import math.random
import math.pow
val NUM_SAMPLES=math.pow(10,8).asInstanceOf[Int]
val count = sc.parallelize(1 to NUM_SAMPLES).filter { _ =>
val x = math.random
val y = math.random
x*x + y*y < 1
}.count()
println(s"Pi is roughly ${4.0 * count / NUM_SAMPLES}")
Python
import random
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
NUM_SAMPLES=10**8
count = sc.parallelize(xrange(0, NUM_SAMPLES)).filter(inside).count()
print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)
Submitting Applications
Source: https://spark.apache.org/docs/latest/submitting-applications.html#master-urls
Linking Spark & Initializing Spark
Python (Recommended)
from pyspark import SparkContext, SparkConf
appName = "caculate-pi"
master = "yarn"
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
Scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
val appName = "caculate-pi"
val master = "yarn"
val conf = new SparkConf().setAppName(appName).setMaster(master)
val sc = new SparkContext(conf)
Java
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.SparkConf;
String appName = "caculate-pi";
String master = "yarn";
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaSparkContext sc = new JavaSparkContext(conf);
The appName parameter is a
name for your application to show on the cluster UI. master is a Spark,
Mesos or YARN cluster URL, or a special “local” string to run in local
mode.
Launching Applications with spark-submit
Python application on a yarn cluster
~$ wget https://pastebin.com/raw/QB1DSCgn --output-document=caculate-pi.py
~$ spark-submit caculate-pi.py
The content of caculate-pi.py
from pyspark import SparkContext, SparkConf
import random
appName = "caculate-pi"
master = "yarn"
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
NUM_SAMPLES=10**6
count = sc.parallelize(xrange(0, NUM_SAMPLES)).filter(inside).count()
print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)
Or you can submit using java JAR file:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
:::danger
以下為spark 1.6所用的方法,spark2版本後已經不產生spark-assembly-*.jar,且多用sbt build,故此方法失效
:::
**Build Spark Application**
```shell
# Create your project directory(done at the local file system)
~$ mkdir ~/lab4/wc -p
# Download WordCount.scala
~$ wget ~/lab4/wc/WordCount.scala
```
Or you can create it manually. The content of WordCount.scala
import org.apache.spark.{ SparkConf, SparkContext }
import org.apache.spark.rdd.RDD
object RunWordCount {
def main(args: Array[String]) {
val sc = new SparkContext(new SparkConf().setAppName("wordCount"))
val textFile = sc.textFile(args(0))
val countsRDD = textFile.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
try {
countsRDD.saveAsTextFile(args(1))
} catch {
case e: Exception => println(“Error!”);
}
sc.stop()
}
}
Then,
# Compile the `WordCount.scala`
~/lab4/wc$ scalac -classpath /usr/local/spark/lib/spark-assembly-1.6.1-hadoop2.4.0.jar WordCount.scala
# Create a jar file
~/lab4$ jar -cvf wc.jar wc/ .
# Create input directory for WordCount
~$ hadoop fs -mkdir -p /user/[username]/input
# Put data to your input directory on HDFS
~$ hadoop fs -put ~/lab4/wc/WordCount.scala /user/[USERNAME]/input
# Submit job to hadoop
~$ spark-submit --class RunWordCount --master yarn-cluster wc.jar input/WordCount.scala output
More
https://spark.apache.org/docs/latest/rdd-programming-guide.html
Reference
https://www.oreilly.com/library/view/learning-spark/9781449359034/ch04.html
https://spark.apache.org/docs/latest/rdd-programming-guide.html
Practice 4-1, 4-2
4-1
Due date: 2019/05/20 23:59
This is a group assignment.
Write a Spark program in Python/Java/Scala and save the code in ~/lab4/ with filename practice1 (For example, pratice1.py).
Please download the input file and upload it to your HDFS home folder:
$ wget https://pastebin.com/raw/P0FXCARK -O practice4-1.txt
$ hadoop fs -put practice4-1.txt
Your program must read the file from hdfs://hadoop-master:8020/user/[your user name]/practice4-1.txt, then print each line that contains “shoe” to stdout(which is your screen, by default).
Hint
The results will look like
Cinderella obeyed, and the Fairy, touching it with her wand, turned it into a grand coach. Then she desired Cinderella to go to the trap, and bring her a rat. The girl obeyed, and a touch of the Fairy’s wand turned him into a very smart coachman. Two mice were turned into footmen; four grasshoppers into white horses. Next, the Fairy touched Cinderella’s rags, and they became rich satin robes, trimmed with point lace. Diamonds shone in her hair and on her neck and arms, and her kind godmother thought she had seldom seen so lovely a girl. Her old shoes became a charming pair of glass slippers, which shone like diamonds.
However, the Prince’s search was rewarded by his finding the glass slipper, which he well knew belonged to the unknown Princess. He loved Cinderella so much that he now resolved to marry her; and as he felt sure that no one else could wear such a tiny shoe as hers was, he sent out a herald to proclaim that whichever lady in his kingdom could put on this glass slipper should be his wife.
4-2
Due date: 2019/05/24 23:59
This is a group assignment.
Write a Spark program in Python/Java/Scala and save the code in ~/lab4/ with filename practice2 (For example, pratice2.py).
Please download the input file and upload it to your HDFS home folder:
$ wget https://pastebin.com/raw/KZJrgL6C -O practice4-2.txt
$ hadoop fs -put practice4-2.txt
Each line in the input file represents a vertex containing x and y coordinates.
Content of the input file:
3.9854848869196324,71.29551177914277
5.480589112961365,90.61946351121573
47.64530232634527,19.706018538612092
65.02517993302833,65.46846854522971
64.8364383782732,12.342955227442086
...
Your program must read the file from hdfs://hadoop-master:8020/user/[your user name]/practice4-2.txt, then print the minimal distance between two vertices to stdout.
Tip
Use cartesian() and reduce(), or min()
SE6023 Lab4 Spark & Scala
tags:
hadoopIntroducing Spark
What is Apache Spark?
Hadoop YARN, Apache Mesos, …
HDFS, Cassandra, OpenStack Swift, Amazon S3, …
Why Spark?
In 2014 Gray Sort competition, a 3rd-party benchmark measuring how fast a system can sort 100 TB of data, shows that Spark has performance advantages than plain MapReduce:
Spark Stack
Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis, or TCP sockets (Source: Introduction to Spark Streaming)
Spark Interactive Shell
We will first introduce the API through Spark’s interactive shell:
pysparkspark-shellthen show you how to write RDD applications in Java, Scala, and Python.
Spark APIs
Spark now provide 3 APIs to make different type of workload easier and more optimized.
Stands for Resilient Distributed Dataset, RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
It is suitable for low-level control on datasets and unstructured data, and the newer API(DataFrames/Datasets) are built on top of RDDs.
We will mainly discuss RDD in this lab session.
Like an RDD, DataFrame is an immutable distributed collection of data. But data is organized into named column which works like a table in a relational database system. It allows higher-level abstraction and provides domain-specific launuage API to manipulate distributed data, make Spark accessible to people other than data engineers.
DataFrame will be merged with Datasets API.
A Dataset is a strongly typed collection of domain-specific objects that can be transformed in parallel using functional or relational operations. Each Dataset also has an untyped view called a DataFrame, which is a Dataset of Row.
DataSet API can:
Core Spark Concept: Resilient Distributed Dataset (RDD)
Spark, every task is expressed in following ways:RDD(s)RDD(s)RDD(s)RDD Operations
RDDs support two types of operations:
map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues …
collect, reduce, count, save, lookupKey …
Source
RDD of Strings
RDD Fault Tolerance in Spark
If the original RDD that was used to create your current partition also isn’t there (neither in memory or on disk) then Spark will have to go one step back again and recompute the previous RDD. In the worst case scenario Spark will have to go all the way back to the original data.
More Information:
Different between
Hadoop MapReduceandRDDIterative Operations
On MapReduce

Incurs substantial overheads due to data replication, disk I/O, and serialization
On Spark RDD

Store intermediate results in a distributed memory
Interactive Operations
On MapReduce

Each query will do the disk I/O on the stable storage
On Spark RDD

If different queries are run on the same set of data repeatedly, this particular data can be kept in memory for better execution times.
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory
(for much faster access when next time you query it)
Creating RDDs
There are two ways to create RDDs
What is the “driver program”?
"The machine where the Spark application process (the one that creates the SparkContext) is running is the “Driver” node, with process being called the Driver process. "
1. Parallelizing Collections
SparkContext’s parallelizemethod on an existing collection in your driver program (a ScalaSeq).Scala
Python
2. Referencing a dataset
Spark supports
Text file RDDs can be created using SparkContext’s textFile method. This method takes an URI for the file (either a local path on the machine, or a hdfs://, s3a://, etc URI)
HTTP/HTTPS URLs is not supported.
Scala
Python
If you are using a path on the local filesystem, the file must also be accessible at the same path on worker nodes. Either copy the file to all workers or use a network-mounted shared file system.
RDD Operations
Basics
Scala
Python
linesis merely a pointer to the file and is not loaded in memory.lineLengthsdefineslineLengthsas the result of a map transformationlineLengthsis not immediately computed, due to lazinessreduceis and action. At this point Spark breaks the computation into tasks to run on separate machines, and each machine runs both its part of the map and a local reduction.If we also wanted to use
lineLengthsagain later, we could add:before the reduce, which would cause
lineLengthsto be saved in memory after the first time it is computed.Working with Key-Value Pairs
Scala
Python
We could also use
counts.sortByKey(), for example, to sort the pairs alphabetically, and finallycounts.collect()to bring them back to the driver program as an array of objects.Transformations
Map
Example:
or
FlatMap
Example:
Above flatMap transformation will convert a line into words. One word will be an individual element of the newly created RDD.
reduceByKey
MapReduce in Java
Spark Scala
More Information: Shuffle operations in Spark(Link)
Actions
Reference
Examples
Using the Spark Shell
Scala:
spark-shellPython:
pysparkWordCount
Scala
Python
Pi Estimation
Therom
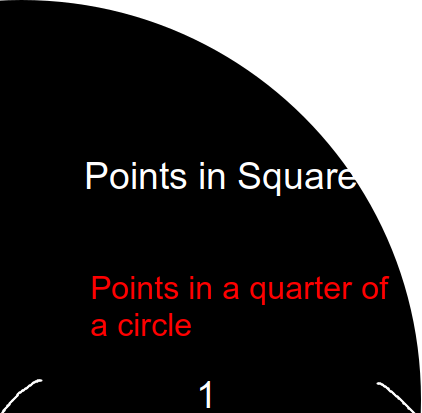
Scala
Python
import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 NUM_SAMPLES=10**8 count = sc.parallelize(xrange(0, NUM_SAMPLES)).filter(inside).count() print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)Submitting Applications
Linking Spark & Initializing Spark
Python (Recommended)
Scala
Java
The
appNameparameter is a name for your application to show on the cluster UI. master is a Spark, Mesos or YARN cluster URL, or a special “local” string to run in local mode.Launching Applications with spark-submit
Python application on a yarn cluster
The content of
caculate-pi.pyMore
>>Hadoop Cluster Information (use UNIX password to log in)<<Reference
https://www.oreilly.com/library/view/learning-spark/9781449359034/ch04.html
https://spark.apache.org/docs/latest/rdd-programming-guide.html
Practice 4-1, 4-2
4-1
Due date: 2019/05/20 23:59
This is a group assignment.
Write a Spark program in Python/Java/Scala and save the code in
~/lab4/with filenamepractice1(For example,pratice1.py).Please download the input file and upload it to your HDFS home folder:
Your program must read the file from
hdfs://hadoop-master:8020/user/[your user name]/practice4-1.txt, then print each line that contains “shoe” to stdout(which is your screen, by default).Hint
The results will look like
4-2
Due date: 2019/05/24 23:59
This is a group assignment.
Write a Spark program in Python/Java/Scala and save the code in
~/lab4/with filename practice2 (For example,pratice2.py).Please download the input file and upload it to your HDFS home folder:
Each line in the input file represents a vertex containing x and y coordinates.
Content of the input file:
Your program must read the file from
hdfs://hadoop-master:8020/user/[your user name]/practice4-2.txt, then print the minimal distance between two vertices to stdout.Tip
Use
cartesian()andreduce(), ormin()