SE6023 Lab2 Pig
Introducing Pig!

- Pig is made up of two pieces:
– The Language used to express data flows, called Pig Latin.
– The execution environment to run Pig Latin programs.
- There are currently two environments:
– Local execution in a single JVM by pig -x local
– Distributed execution on a Hadoop cluster (Our focus!)
- Pig handles semi-structure data (半結構化資料)
Key Properties
- Easy of programming.
It is trivial to achieve parallel execution of simple, “embarrassingly
parallel” data analysis tasks. Complex tasks comprised of multiple
interrelated data transformations are explicitly encoded as data flow
sequences, making them easy to write, understand, and maintain.
- Optimization opportunities.
The way in which tasks are encoded permits the system to optimize their
execution automatically, allowing the user to focus on semantics rather
than efficiency.
- Extensibility.
Users can create their own functions to do special-purpose processing.
Definitions and Data Types
Relations, Bags, Tuples, Fields
Pig Latin statements work with relations. A relation can be defined as follows:
A field is a piece of data.
A tuple is an ordered set of fields.
A bag is a collection of tuples.
A relation is a bag (more specifically, an outer bag).
For example,
> A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, gpa:float);
> DUMP A;
(John,18,4.0F) <-tuple
(Mary,19,3.8F)
(Bill,20,3.9F)
(Joe,18,3.8F)
|
1st Field |
2nd Field |
3th Field |
| Data type |
chararray |
int |
float |
| Positional notation(generated by system) |
$0 |
$1 |
$2 |
| Possible name (assigned by you using a schema) |
name |
age |
gpa |
| Field value (for the first tuple) |
John |
18 |
4.0 |
For debugging purposes and ease of comprehension, it is better to use field names.
| Type |
Example |
| tuple |
(1,‘programmer’) |
| bag |
{(1,‘programmer’),(2),(3,‘apple’)} |
| Conventions |
Description |
Example |
| ( ) |
Parentheses enclose one or more items. |
Multiple items: (1, abc, (2,4,6) ) |
Expressions
In Pig Latin, expressions are language constructs used with the FILTER, FOREACH, GROUP, and SPLIT operators as well as the eval functions.
For example:
#
> X = GROUP A BY f2*f3;
#
> X = FOREACH A GENERATE CONCAT(a,b);
#
> X = FILTER A BY (f1==8) OR (NOT (f2+f3 > f1));
Reference: https://pig.apache.org/docs/latest/basic.html
Pig Hands-on
Note
Replace all occurrences of a000000000 with your username.
Import data
import test.txt
#
~$ wget pdc19.csie.ncu.edu.tw/lab2/test.txt
~$ cat test.txt
1950 11 1
1950 12 2
1955 11 1
1954 12 2
1953 13 1
1954 12 2
...
~$ hadoop fs -put ./test.txt /user/a000000000/test.txt
#
# pig -x tez
# pig -d WARN
~$ pig
#
#
grunt> records = load '/user/a000000000/test.txt' using PigStorage(' ') as (year:chararray, temperature:int, quality:int);
#
grunt> describe records;
records: {year: chararray,temperature: int,quality: int}
#
grunt> dump records;
(1950,11,1)
(1950,12,2)
(1955,11,1)
(1954,12,2)
(1953,13,1)
(1954,12,2)
(1953,11,1)
(1952,12,2)
(1951,13,1)
(1952,14,2)
(1953,13,2)
(1954,12,1)
(1955,11,1)
(1956,12,2)
(1954,13,2)
grunt>
Data Processing
- Grouping: Group data in simple relation
- Filtering: Removes unwanted rows from a relation
#
grunt> rec1 = filter records by temperature >11 and (quality == 0 or quality == 2);
grunt> dump rec1;
(1950,12,2)
(1954,12,2)
(1954,12,2)
(1952,12,2)
(1952,14,2)
(1953,13,2)
(1956,12,2)
(1954,13,2)
#
grunt> rec2 = group rec1 by year;
grunt> describe rec2;
rec2: <group: charryareray, rec1 <year: chararry, temperature: int, quality: int>>
grunt> dump rec2;
(1950,{(1950,12,2)})
(1952,{(1952,12,2),(1952,14,2)})
(1953,{(1953,13,2)})
(1954,{(1954,12,2),(1954,12,2),(1954,13,2)})
(1956,{(1956,12,2)})
Reduce
foreach: Processes every row to generate a derived set of rowsgenerate: using a GENERATE clause to define the fields in each derived row.
grunt> maxt = FOREACH rec2 GENERATE group, MAX(rec1.temperature);
grunt> dump maxt
(1950,12)
(1952,14)
(1953,13)
(1954,13)
(1956,12)
Illustrate
Show where the result come from
grunt> ILLUSTRATE maxt
----------------------------------------------------------------------------
| records | year:chararray | temperature:int | quality:int |
----------------------------------------------------------------------------
| | 1952 | 14 | 2 |
| | 1952 | 12 | 2 |
| | 1953 | 11 | 1 |
| | 1954 | 12 | 1 |
| | 1952 | 12 | 0 |
----------------------------------------------------------------------------
-------------------------------------------------------------------------
| rec1 | year:chararray | temperature:int | quality:int |
-------------------------------------------------------------------------
| | 1952 | 14 | 2 |
| | 1952 | 12 | 2 |
| | 1952 | 12 | 0 |
-------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------------------------
| rec2 | group:chararray | rec1:bag{:tuple(year:chararray,temperature:int,quality:int)} |
---------------------------------------------------------------------------------------------------------------------
| | 1952 | {} |
| | 1952 | {} |
---------------------------------------------------------------------------------------------------------------------
---------------------------------------------
| maxt | group:chararray | :int |
---------------------------------------------
| | 1952 | 14 |
---------------------------------------------
Write your first pig scripts
records = load '/user/a000000000/test.txt' using PigStorage(' ') as (year:chararray, temperature:int, quality:int);
rec1 = filter records by temperature >11 and (quality == 0 OR quality == 2);
rec2 = group rec1 by year;
maxt = foreach rec2 generate group, MAX(rec1.temperature);
dump maxt;
~$ pig test.pig
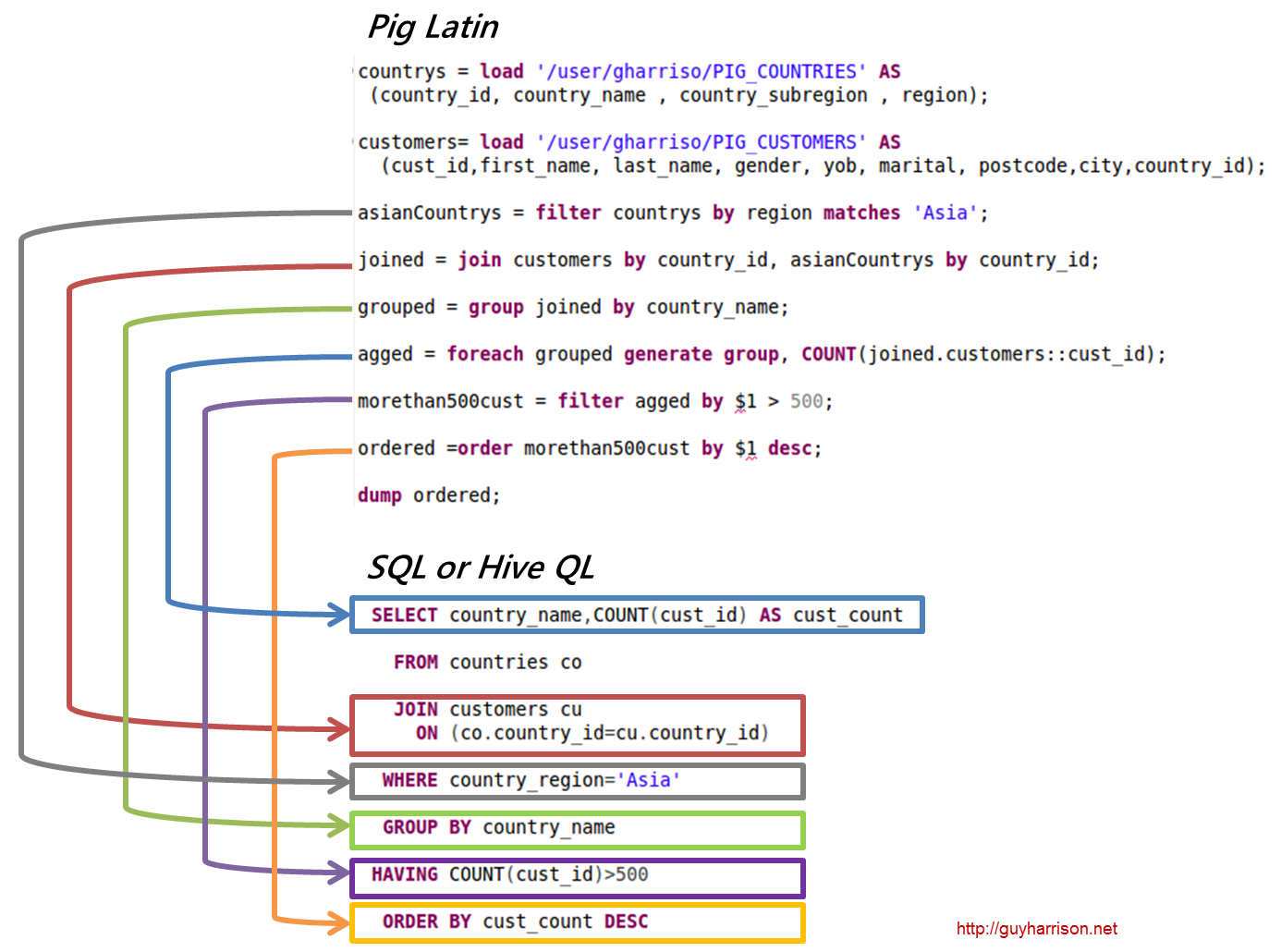
Comparing with RDBMS/Hive
| Name |
Description |
| Database |
SQL commands, pre-defined schema |
| Hadoop Hive |
SQL-Like commands on Hadoop HDFS |
| Pig |
Data flow commands and runtime schema on Hadoop HDFS |
Practices
Practice1
Test Input
pdata.txt
Write a pig latin script to:
- Load
pdata.txt. Collect all the data after 1951 (1951 is not included)
- Filter the data where quality =1
- Group the data by temperature, and then calculate the largest year for each temperature
Save your script named studentID_practice1.pig in your home directory/lab2 (~/lab2).
Expected value
(0,1991)
(3,1991)
(4,1989)
(5,1957)
(9,1993)
(10,1967)
(11,1961)
(13,1958)
(15,1972)
(16,1989)
(17,1976)
(18,1978)
(19,1967)
(20,1977)
(22,1994)
(23,1973)
(24,1996)
(25,1996)
(26,1983)
(28,1995)
(32,1970)
(34,1954)
(35,1993)
(37,1986)
(38,1985)
(39,1982)
(40,1993)
(42,1958)
(43,1985)
(44,1986)
(45,1987)
(46,1996)
(47,1982)
(48,1978)
(49,1985)
(51,1973)
(54,1989)
(55,1973)
(56,1965)
(58,1966)
(59,1980)
(60,1988)
(62,1998)
(64,1959)
(65,1989)
(66,1965)
(68,1993)
(69,1998)
(70,1989)
(71,1983)
(72,1952)
(73,1975)
(74,1989)
(75,1998)
(77,1987)
(78,1965)
(79,1992)
(81,1976)
(83,1976)
(84,1999)
(85,1959)
(88,1991)
(89,1991)
(90,1980)
(91,1991)
(92,1995)
(94,1995)
(95,1966)
(96,1979)
(97,1965)
(98,1975)
Practice2
Test Input
pbad.txt
Write a pig latin script:
- Load
pbad.txt, remove bad data.
- Split good data into new data if quality matches ‘[0123456789]’, and old data if quality does not match ‘[0123456789]’.
- Convert temperature in degrees Celsius (°C) to in degrees Fahrenheit (°F)
- Use
dump to show the maximum temperature with decimal fraction for each year in the old data
Tip

Save your script named studentID_practice2.pig in your home directory/lab2 (~/lab2).
Expected value
(1900,156.2)
(1901,172.4)
(1902,123.8)
(1903,147.2)
(1904,111.2)
(1905,190.4)
(1907,95.0)
(1908,64.4)
(1909,185.0)
(1910,77.0)
(1911,176.0)
(1912,194.0)
(1913,93.2)
(1914,165.2)
(1915,140.0)
(1916,206.6)
(1917,161.6)
(1918,68.0)
(1919,176.0)
(1920,122.0)
(1921,109.4)
(1922,82.4)
(1923,46.4)
(1924,206.6)
(1925,147.2)
(1926,204.8)
(1927,197.6)
(1928,167.0)
(1929,163.4)
(1930,159.8)
(1931,188.6)
(1932,208.4)
(1933,197.6)
(1934,208.4)
(1935,183.2)
(1936,183.2)
(1937,179.6)
(1938,177.8)
(1939,95.0)
(1940,95.0)
(1941,120.2)
(1942,104.0)
(1944,190.4)
(1945,190.4)
(1946,136.4)
(1947,156.2)
(1948,165.2)
(1949,125.6)
(1950,208.4)
(1951,104.0)
(1952,114.8)
(1953,190.4)
(1954,132.8)
(1955,33.8)
(1956,116.6)
(1957,156.2)
(1958,210.2)
(1959,201.2)
(1960,210.2)
(1961,195.8)
(1962,192.2)
(1963,50.0)
(1964,210.2)
(1965,183.2)
(1966,185.0)
(1967,197.6)
(1968,206.6)
(1969,199.4)
(1970,42.8)
(1971,188.6)
(1972,186.8)
(1973,210.2)
(1974,208.4)
(1975,195.8)
(1976,145.4)
(1977,174.2)
(1978,57.2)
(1981,183.2)
(1982,33.8)
(1983,190.4)
(1984,96.8)
(1985,174.2)
(1986,53.6)
(1988,177.8)
(1989,98.6)
(1990,60.8)
(1991,149.0)
(1993,50.0)
(1994,167.0)
(1997,179.6)
(1998,206.6)
(1999,195.8)
SE6023 Lab2 Pig
tags:
hadoopIntroducing Pig!
– The Language used to express data flows, called Pig Latin.
– The execution environment to run Pig Latin programs.
– Local execution in a single JVM by
pig -x local– Distributed execution on a Hadoop cluster (Our focus!)
Key Properties
It is trivial to achieve parallel execution of simple, “embarrassingly parallel” data analysis tasks. Complex tasks comprised of multiple interrelated data transformations are explicitly encoded as data flow sequences, making them easy to write, understand, and maintain.
The way in which tasks are encoded permits the system to optimize their execution automatically, allowing the user to focus on semantics rather than efficiency.
Users can create their own functions to do special-purpose processing.
Definitions and Data Types
Relations, Bags, Tuples, Fields
Pig Latin statements work with
relations. Arelationcan be defined as follows:For example,
> A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, gpa:float); > DUMP A; (John,18,4.0F) <-tuple (Mary,19,3.8F) (Bill,20,3.9F) (Joe,18,3.8F)(1, abc, (2,4,6) )Expressions
In Pig Latin, expressions are language constructs used with the
FILTER,FOREACH,GROUP, andSPLIToperators as well as the eval functions.For example:
## An arithmetic expression could look like this: > X = GROUP A BY f2*f3; ## A string expression could look like this, where a and b are both chararrays: > X = FOREACH A GENERATE CONCAT(a,b); ## A boolean expression could look like this: > X = FILTER A BY (f1==8) OR (NOT (f2+f3 > f1));Pig Hands-on
Note
Replace all occurrences of
a000000000with your username.Import data
import test.txt
## Retrieve test data ~$ wget pdc19.csie.ncu.edu.tw/lab2/test.txt ~$ cat test.txt 1950 11 1 1950 12 2 1955 11 1 1954 12 2 1953 13 1 1954 12 2 ... ~$ hadoop fs -put ./test.txt /user/a000000000/test.txt ## Run pig # pig -x tez # will make some query faster, but will fail to ILLUSTRATE # pig -d WARN # will hide some annoying INFO messages ~$ pig ## Load data of test.txt ## Use PigStorage(' ') to use ' '(space) as the delimiter. grunt> records = load '/user/a000000000/test.txt' using PigStorage(' ') as (year:chararray, temperature:int, quality:int); ## Show the structure of a relation grunt> describe records; records: {year: chararray,temperature: int,quality: int} ## Show records in test.txt grunt> dump records; (1950,11,1) (1950,12,2) (1955,11,1) (1954,12,2) (1953,13,1) (1954,12,2) (1953,11,1) (1952,12,2) (1951,13,1) (1952,14,2) (1953,13,2) (1954,12,1) (1955,11,1) (1956,12,2) (1954,13,2) grunt>Data Processing
## Data filtering grunt> rec1 = filter records by temperature >11 and (quality == 0 or quality == 2); grunt> dump rec1; (1950,12,2) (1954,12,2) (1954,12,2) (1952,12,2) (1952,14,2) (1953,13,2) (1956,12,2) (1954,13,2) ## Data Grouping grunt> rec2 = group rec1 by year; grunt> describe rec2; rec2: <group: charryareray, rec1 <year: chararry, temperature: int, quality: int>> grunt> dump rec2; (1950,{(1950,12,2)}) (1952,{(1952,12,2),(1952,14,2)}) (1953,{(1953,13,2)}) (1954,{(1954,12,2),(1954,12,2),(1954,13,2)}) (1956,{(1956,12,2)})Reduce
foreach: Processes every row to generate a derived set of rowsgenerate: using aGENERATEclause to define the fields in each derived row.grunt> maxt = FOREACH rec2 GENERATE group, MAX(rec1.temperature); grunt> dump maxt (1950,12) (1952,14) (1953,13) (1954,13) (1956,12)Illustrate
Show where the result come from
grunt> ILLUSTRATE maxt ---------------------------------------------------------------------------- | records | year:chararray | temperature:int | quality:int | ---------------------------------------------------------------------------- | | 1952 | 14 | 2 | | | 1952 | 12 | 2 | | | 1953 | 11 | 1 | | | 1954 | 12 | 1 | | | 1952 | 12 | 0 | ---------------------------------------------------------------------------- ------------------------------------------------------------------------- | rec1 | year:chararray | temperature:int | quality:int | ------------------------------------------------------------------------- | | 1952 | 14 | 2 | | | 1952 | 12 | 2 | | | 1952 | 12 | 0 | ------------------------------------------------------------------------- --------------------------------------------------------------------------------------------------------------------- | rec2 | group:chararray | rec1:bag{:tuple(year:chararray,temperature:int,quality:int)} | --------------------------------------------------------------------------------------------------------------------- | | 1952 | {} | | | 1952 | {} | --------------------------------------------------------------------------------------------------------------------- --------------------------------------------- | maxt | group:chararray | :int | --------------------------------------------- | | 1952 | 14 | ---------------------------------------------Write your first pig scripts
Comparing with RDBMS/Hive
Practices
Deadline: 4/22 pm12:00
Practice1
Write a pig latin script to:
pdata.txt. Collect all the data after 1951 (1951 is not included)Save your script named
studentID_practice1.pigin your home directory/lab2 (~/lab2).Expected value
Practice2
Write a pig latin script:
pbad.txt, remove bad data.dumpto show the maximum temperature with decimal fraction for each year in the old dataTip

Save your script named
studentID_practice2.pigin your home directory/lab2 (~/lab2).Expected value