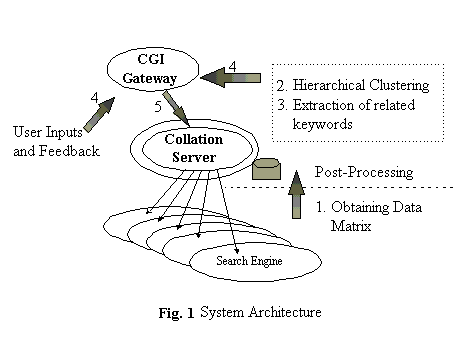
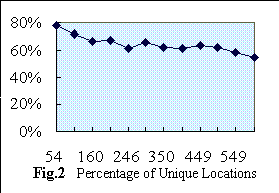
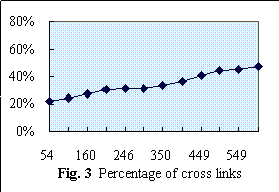
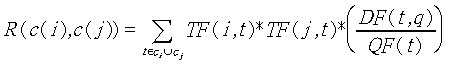The recording of the "query profile" and the "category profile" are
prepared not only for the ordinary search but also used as a reference for
the filtering of any on-line magazines. That is, the server can highlight
the out links of a homepage according to the profiles to help the user
through the browsing of the homepage. In addition, the system can
periodically retrieve related information from new published data based on
the analysis of the two profiles. These additional functions can be achieved
with the technology of data mining which is a new addressed topics in the
recent research.
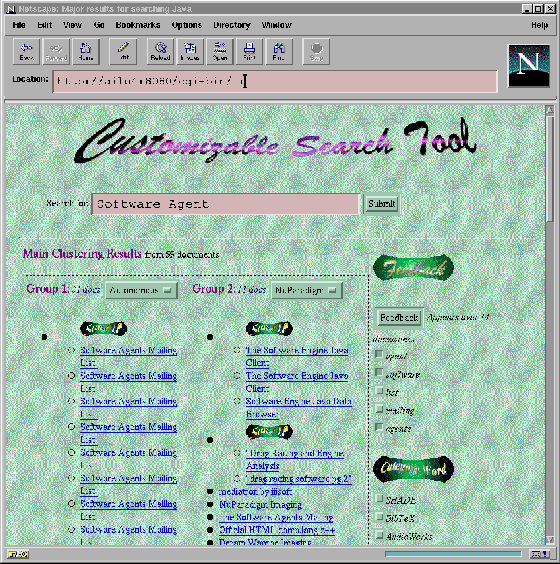
**The prototype of our system is also available at
http://ails6.csie.ntu.edu.tw/~chia/air.html
References
[BDH+94] C.M. Bowman, P.B. Danzig, D.R. Hardy, M.F. Schwartz,
"Scalable Internet Resource Discovery: Research Problems
and Approaches," Comm. of ACM, Vol. 37, No. 8, pp.98-107,
1994
[BDH+94] C. Mic Bowman, P.B. Danzig, D.R. Hardy, U. Manber and
M.F. Schwartz, "The Harvest Information Discovery and Access
System", Techical Report at U. Colorado.
[Cor71] R.M. Cormack, "A Review of Classification,"
Journal of the Royal Statistical Society, Series A. 134, pp. 321-353
[Dre95] Daniel Dreilinger, "Integrating Heterogeneous WWW
Search Engines", May 1995. Ftp://132.239.54.5/savvy/report.ps.gz
[E95] Learning to understand information on the Internet. (IJCAI-95).
[EW94] O. Etzioni, D. Weld, "A Softbot-Based Interface to
the Internet," Comm. of ACM, Vol. 37, No. 7, July 1994, pp.72-76
http://www.cs.washington.edu/research/softbots
[FO95] C. Faloutsos and D.W. Oard, "A Survey of Information
Retrieval and Filtering Methods," University of Maryland,
Technical Reports CS-TR-3514
[HL95] T.W.C. Huibers and B. van Linder, "Formalising Intelligent
Information Retrieval Agents," Technical Report, Utrecht
University.
[KG94] Q. Kong and J. Gottschalk, "Information Retrieval
Standard and Applications," presented at BISCM'94 - Beijing.
http://www.dstc.edu.au/RDU/reports
[Pin94] B. Pinkerton, "Finding What People Want: Experiences
with the WebCrawler," Second International WWW Conference
'94, July 1994, Chicago, USA, Oct. 1994.
http://info.webcrawler.com/bp/WWW94.html
[Rij79] C.J. van Rijsbergen, Information Retrieval. Butterworths,
London, England, 1979, 2nd edition.
[Rom84] H. C. Romesburg, Cluster Analysis for Researchers. Wadsworth,
Belmont, California, 1984.
[SE95] E. Selberg, O. Etzioni, "Multi-Engine Search And Comparison
Using The MetaCrawler," Proceedings of the Fouth World Wide
Web Conference '95, Boston USA. Dec. 1995.
[YL96] B. Yuwono and Dik L. Lee, "WISE: A World Wide Web
Resource Database System," To appear in IEEE Trans. on Knowledge
and Data Engineering Special Issue on Digital Library.
URLs
[AltaVista] http://www.altavista.digital.com
[Magellan] http://searcher.mckinley.com
[Infoseek] http://ultra.infoseek.com
[Lycos] http://lycos.cs.cmu.edu.tw
[WebCrawler] http://webcrawler.com
[Roget's] Roget's
Thesaurus: http://www2.thesaurus.com/thesaurus
[WISE] http://www.cs.ust.hk/cgi-bin/IndexServer
[MetaCrawler] http://www.metacrawler.com